

Classifiche credibili? La Grande Guida CENSIS Repubblica offre davvero «una panoramica completa e approfondita sull’universo accademico italiano. Una vera e propria bussola soprattutto per le future matricole»? Qualche dubbio è legittimo se nella classifica della ricerca di Ingegneria industriale e dell’informazione finisce al terzo posto un ateneo senza nessun corso di laurea in ingegneria. Incidente di percorso o sintomo di carenze strutturali? Per capirlo, analizziamo in dettaglio indicatori e metodi delle classifiche CENSIS-Repubblica, discutendone incongruenze, criticità e fragilità.
Il 22 luglio 2014 è stata pubblicata l’edizione 2014-15 della Grande Guida Università curata dal CENSIS per conto del quotidiano la Repubblica. Anche se non avete sborsato 9,90 Euro per le 647 pagine della guida, al seguente link trovate una sintesi delle classifiche:
Grande Guida Università 2014- 2015 CLASSIFICHE
Questa era la presentazione:
La Grande Guida Università di Repubblica (in collaborazione con Censis) torna in edicola per il quindicesimo anno consecutivo con lo scopo di continuare ad offrire a studenti, genitori e al mondo universitario ciò che è difficile trovare in un unico prodotto: una panoramica completa e approfondita sull’universo accademico italiano. Una vera e propria bussola soprattutto per le future matricole che dopo la cosiddetta riforma Gelmini si trovano a dover fare i conti con le nuove strutture degli atenei che prevedono la graduale scomparsa delle facoltà a favore di altre organizzazioni come dipartimenti o scuole. Fatto che ha reso necessario un riassestamento delle classifiche proposte dal Censis, che rappresentano il valore aggiunto della Grande Guida Università. Le valutazioni, suddivise in didattica e ricerca, consentiranno al lettore di fare una scelta più precisa in relazione all’interesse personale e agli obiettivi di studio e di lavoro.
Il messaggio è chiaro: il fulcro della Guida sono le classifiche, che grazie ad una “panoramica completa ed approfondita” aiuterebbero le matricole a scegliere in modo più preciso e consapevole.
È ormai una decina d’anni che l’istruzione universitaria deve fare i conti con una vera e propria “febbre dei ranking” che spazia dalle classifiche internazionali a quelle nazionai. Nonostante l’ampia risonanza a loro attribuiita da tutti i mezzi di informazione, sono ben note agli esperti le numerose falle tecniche che in passato hanno dato luogo a risultati talmente paradossali da gettare più di un’ombra sulla credibilità di questi ranking.

Nel 2010, nella sua classifica di impatto citazionale, Times Higher Education ha collocato l’Università di Alessandria d’Egitto al quarto posto mondiale davanti a Stanford e Harvard grazie all’exploit bibliometrico di un ricercatore che aveva pubblicato non meno di 320 articoli nella rivista da lui diretta (Times Higher Education World University Rankings: science or quackery?). Di un’altra classifica famosa, il Ranking QS, è stata compilata la Top 10 degli svarioni più clamorosi (Ranking QS: la Top 10 degli svarioni più spettacolari). La progenitrice delle classifiche internazionali, la Classifica di Shanghai, è stata oggetto di una dettagliata stroncatura metodologica, il cui responso finale è stato tranchant:
any of our MCDM [Multiple Criteria Decision Making NdR] student that would have proposed such a methodology in her Master’s Thesis would have surely failed according to our own standards.
Billaut et al. “Should you believe in the Shanghai ranking”, Scienometrics 2010
le tabelle che per comodità di visualizzazione riuniscono nel rapporto i risultati delle valutazioni nelle varie Aree non devono essere utilizzate per costruire graduatorie di merito tra le aree stesse, un esercizio senza alcun fondamento metodologico e scientifico

Prologo: Scienze Motorie sul podio … dell’ingegneria
 Il terzo posto di Roma Foro Italico appare sorprendente. Infatti, quell’ateneo non ospita nessun corso di laurea in Ingegneria. Basta una veloce visita al suo sito, per scoprire che l’offerta formativa è concentrata nel campo delle scienze motorie e sportive.
Il terzo posto di Roma Foro Italico appare sorprendente. Infatti, quell’ateneo non ospita nessun corso di laurea in Ingegneria. Basta una veloce visita al suo sito, per scoprire che l’offerta formativa è concentrata nel campo delle scienze motorie e sportive.
- Correttezza della metodologia usata per aggregare gli indicatori
- Natura e adeguatezza degli indicatori
- Adeguatezza del database usato per valutare la ricerca scientifica
- Correttezza e robustezza degli indicatori bibliometrici
1. Correttezza della metodologia usata per aggregare gli indicatori
- la percentuale di studenti che usufruiscono del programma Erasmus
- il numero di università straniere ospitanti diviso per il totale degli iscritti
- la percentuale degli studenti stranieri sul totale degli iscritti

- la percentuale di studenti che usufruiscono del programma Erasmus
- il numero di università straniere ospitanti diviso per il totale degli iscritti
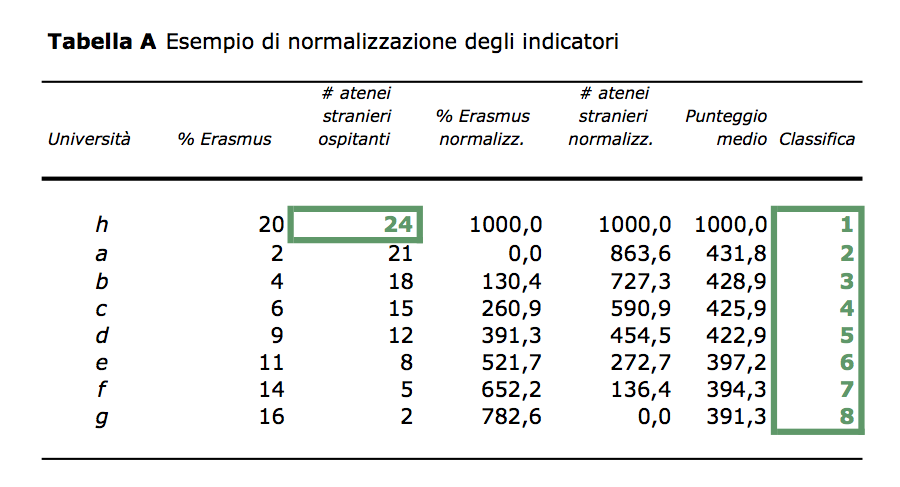
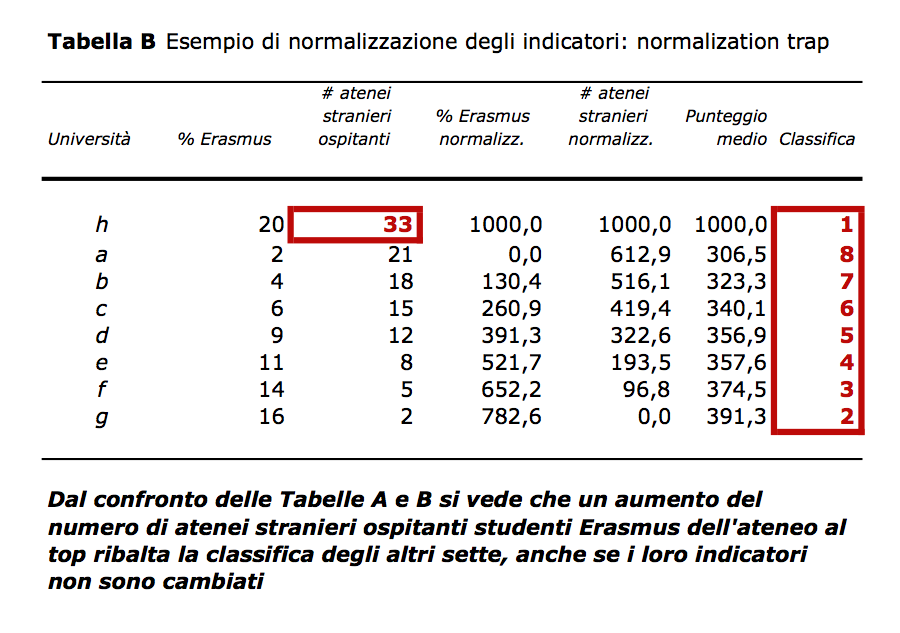
The aggregation technique used is flawed
2. Natura e adeguatezza degli indicatori
Nella Grande Guida ci sono tre tipi di classifiche:
- Le classifiche globali degli atenei statali (ripartiti in quattro sottoclassifiche dimensionali: mega, grandi, medi, piccoli) e degli atenei statali (con tre sottoclassifiche: grandi, medi, piccoli).
- Le classifiche della didattica, ripartite in 14 sottoclassifiche, una per ogni area scientifica.
- Le classifiche della ricerca, ripartite in 14 sottoclassifiche, una per ogni area scientifica.
Le classifiche sono ottenute aggregando (con il metodo appena discusso) numerosi indicatori numerici che misurano diversi aspetti, dai servizi e le strutture, fino alla qualità della didattica e della ricerca. Nello scorrere la lista degli indicatori, è difficile trovare un filo di Arianna, ma sembra che abbia prevalso l’utilizzo dei dati numerici che erano più facilmente a disposizione.
Le classifiche globali sono ottenute tramite la media aritmetica dei 5 voti ottenuti nelle seguenti famiglie di indicatori:
- Servizi: pasti e alloggi. Fonte: MIUR.
- Borse e contributi: spesa. Fonte: MIUR.
- Strutture: posti in aule, bblioteche e laboratori. Fonte: ANVUR
- Web: Punteggio assegnato ai siti internet degli atenei sulla base della funzionalità e dei contenuti. Fonte: Censis 2014.
- Internazionalizzazione: iscritti stranieri, studenti che hanno trascorso periodi all’estero, studenti stranieri che hanno trascorso periodi nell’ateneo.
La voce “Web” è quella meno verificabile, quasi un Jolly che il CENSIS è libero di giocare a sua discrezione. Tutti le altre voci derivano da indicatori normalizzati in funzione del numero di studenti.
I pesi attribuiti agli indicatori sono uniformi, ma la procedure di normalizzazione tra 0 e 1000, lungi dall’essere neutrale, può spostare i voti, in modo poco prevedibile. Per esempio, nella voce “Servizi” l’Università della Calabria stacca tutte le altre ed il gioco della normalizazione schiaccia verso il basso i punteggi “Servizi” del resto degli atenei. L’inverso succede per il “Web”, dove tre università (Sannio, Napoli Parthenope e Chieti) rimangono staccate a fondo classifica, con la conseguenza di spingere verso l’alto i punteggi “Web” dei rimanenti atenei. La conseguenza è che gli atenei che stanno a metà nell classifica “Servizi” si vedono attribuiti 76 punti su 110, mentre chi sta a metà nella classifica “Web”, riceve 95 punti su 110.
Un sostanziale arretramento della prima università della sottoclassifica “Servizi” o un sostanziale avanzamento delle ultime tre università della sottoclassifica “Web” sarebbero capaci – da soli – di modificare sensibilmente tutti i punteggi degli altri atenei (e la loro classifica finale). Questa forma di instabilità è una conseguenza – del tutto prevedibile – della normalization trap.
Le classifiche della didattica sono basate sulla media di due voti relativi alle seguenti famiglie di indicatori:
- Produttività: tasso di persistenza tra il primo ed il secondo anno, indice di regolarità dei crediti, tasso di iscritti regolari, tasso di regolarità dei laureati. Fonte: MIUR.
- Rapporti internazionali: mobilità degli studenti in uscita, università ospitanti, iscritti stranieri. Fonte: INDIRE, MIUR.
Gli indicatori della produttività appaiono in buona parte sovrapponibili e nel complesso premiano gli atenei con meno abbandoni e fuori corso. Gli indicatori dei rapporti internazionali includono il numero di università straniere che hanno ospitato gli studenti “Erasmus”, un indicatore che non sembra particolarmente significativo.
Le classifiche della ricerca sono basate sulla media di due voti relativi alle seguenti famiglie di indicatori:
- Ricerca: unità di ricerca finanziate dai programmi PRIN per docente di ruolo, finanziamento medio dei programmi PRIN, progetti presentati nel programma PRIN per docente di ruolo, tasso di successo nei programmi PRIN, progetti di ricerca VII Programma Quadro per docente di ruolo. Fonte: MIUR e uffici ricerca degli atenei.
- Poduttività scientifica: h-index normalizzato medio, pubblicazioni per docente di ruolo, citazioni per pubblicazione. Fonte: Google Scholar.
Alcuni indicatori sono privi di significato. Per esempio, per primeggiare nell’indicatore che misura il finanziamento medio dei programmi PRIN, basta un solo progetto PRIN finanziato ma di grande entità. Anche il tasso di successo nei programmi PRIN premierebbe chi presenta un unico progetto e lo vede finanziato. Difficile interpretare questo pot-pourri di indicatori in contraddizione tra loro: un ateneo che svetta per numero di progetti PRIN presentati e finanziati potrebbe essere penalizzato negli indicatori del finanziamento medio e del tasso di successo.
Altrettano se non più problematici sono gli indicatori di produttività scientifica adottati dal CENSIS alla cui discussione sono dedicate le prossime due sezioni.
3. Adeguatezza del database usato per valutare la ricerca scientifica
- PS1 h-index normalizzato medio (2008-2012)
- PS2 Pubblicazioni/docenti di ruolo (2008-2012)
- PS3 citazioni/pubblicazioni (2008-2012)
Il CENSIS non utilizza nessuno di questi due database, ma ricorre a Google Scholar, che è un motore di ricerca specializzato nella letteratura scientifica. In virtù della maggiore eterogeneità dei contenuti accessibili attraverso Google Scholar, non è la prima volta che se ne propone l’uso per una valutazione bibliometrica estesa anche nel campo delle scienze umane e sociali. Ma è una soluzione illusoria. Google Scholar è uno strumento inadeguato allo scopo, anche perché introduce distorsioni grossolane come mostrato a più riprese su Roars (qui e qui). In entrambi gli esempi citati, alle intrinseche debolezze di Google Scholar si aggiungevano le distorsioni introdotte da un’interfaccia fatta in casa, denominata Scholar Search, sviluppata e mantenuta dal Molecolar Genetics Group dell’Università di Roma Tor Vergata, sotto il coordinamento di Gianni Cesareni e Daniele Peluso. Nella Grande Guida non è precisato se si sia fatto ricorso o meno Scholar Search, ma a pagina 10 della versione cartacea si ringraziano “il prof. Cesareni e il dr. Peluso per il supporto sui dati Google Scholar“.
A prescindere dall’utilizzo dell”interfaccia Scholar Search, rimane il fatto che la letteratura scientometrica ritiene Google Scholar inutilizzabile ai fini della valutazione. Prima di tutto, come già osservato su Roars, Google Scholar non indicizza tutti gli articoli pubblicati e nemmeno tutte le riviste:
Tali problematiche crescono in maniera esponenziale se si prende in conto che non tutti i testi sono liberamente scansionabili dal crawler di Google, sia per ragioni legali legate ai diritti d’autore, sia per ragioni puramente tecniche legate alle policy interne e alle tecnologie informatiche dei differenti database che accolgono le diverse pubblicazioni scientifiche.
Un ulteriore problema è quello di disambiguare i docenti che hanno degli omonimi. Un problema tutt’altro che banale che non si riesce a risolvere con espedienti a buon mercato come quelli messi in atto dall’interfaccia Scholar Search già citata. Nella versione attualmente on-line, per estrarre le pubblicazioni di un ipotetico docente padovano “Tizio Fittizio”, Scholar Search utilizza la seguente interrogazione:
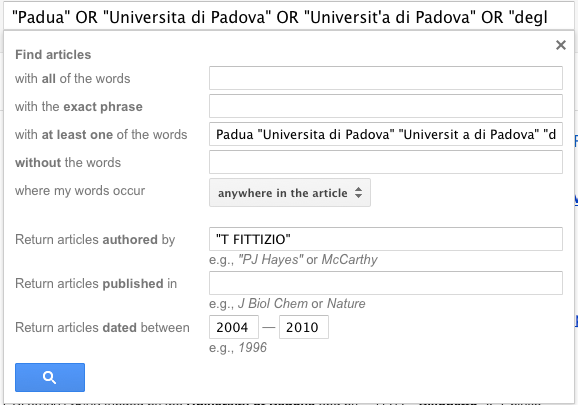 Se nell’ateneo padovano esistesse un ricercatore di nome “Tito Fittizio” (il fratello, per esempio), l’interrogazione metterebbe nello stesso calderone le pubblicazioni di Tizio e Tito. Per inciso, lo stesso accadrebbe se Tito lavorasse nella sede padovana di un istituto del CNR e avesse l’abitudine di usare “Padua” nell’affiliazione. Ma quanto incidono questi equivoci? A suo tempo avevamo mostrato che, come conseguenza della disambiguazione fai-da-te di Scholar Search, i tre ricercatori più produttivi (secondo Scholar Search) del Dipartimento di Scienze Politiche e Sociali dell’Università di Pavia fossero tali solo in virtù della loro omonimia con altri colleghi dell’ateneo e che almeno il 50% delle citazioni attribuite a quel dipartimento erano frutto di omonimie (Scholar Search e la leggenda del “rettore fannullone”). A riprova delle pesanti distorsioni, basterà ricordare che le percentuali di inattivi nelle aree umanistiche pavesi 10-12 e 14 risultavano sovrastimate di più di 50 punti percentuali rispetto alla realtà.
Se nell’ateneo padovano esistesse un ricercatore di nome “Tito Fittizio” (il fratello, per esempio), l’interrogazione metterebbe nello stesso calderone le pubblicazioni di Tizio e Tito. Per inciso, lo stesso accadrebbe se Tito lavorasse nella sede padovana di un istituto del CNR e avesse l’abitudine di usare “Padua” nell’affiliazione. Ma quanto incidono questi equivoci? A suo tempo avevamo mostrato che, come conseguenza della disambiguazione fai-da-te di Scholar Search, i tre ricercatori più produttivi (secondo Scholar Search) del Dipartimento di Scienze Politiche e Sociali dell’Università di Pavia fossero tali solo in virtù della loro omonimia con altri colleghi dell’ateneo e che almeno il 50% delle citazioni attribuite a quel dipartimento erano frutto di omonimie (Scholar Search e la leggenda del “rettore fannullone”). A riprova delle pesanti distorsioni, basterà ricordare che le percentuali di inattivi nelle aree umanistiche pavesi 10-12 e 14 risultavano sovrastimate di più di 50 punti percentuali rispetto alla realtà.
Non a caso, la letteratura scientometrica non annovera Google Scholar tra le basi dati utilizzabili per svolgere valutazioni della ricerca. Come scrive Diane Hicks,
[Google Scolar] is not in a form usable for structured analysis. Basically this is beacause GS is not built from structured records, that is from metadata fields. Rather that using the author, affiliation, reference etc. data provided by publishers, GS parses full text to obtains its best guess for these items.
4. Correttezza e robustezza degli indicatori bibliometrici
Ritorniamo ora all’indicatore PS (Produttività scientifica) che dipende a sua volta dai 3 indicatori PS1-PS3, ovvero:
- PS1 h-index normalizzato medio (2008-2012)
- PS2 Pubblicazioni/docenti di ruolo (2008-2012)
- PS3 citazioni/pubblicazioni (2008-2012)

The normalized H index is the Z score of the specific academic calculated with respect to the distribution of the H indexes of the SSD of pertinence.
 Si tratta di una classica normalizzazione statistica, che ha l’effetto di produrre un indicatore con media nulla e varianza unitaria.
Si tratta di una classica normalizzazione statistica, che ha l’effetto di produrre un indicatore con media nulla e varianza unitaria.In the left one Institutions are ranked according to the sum of the normalized H index while in the right one the ranking is according to average “normalized H index”
normalized H index del gruppo A = (10 + 10 + 10)/3 = 10
normalized H index del gruppo B = (30 + 30 + 30)/3 = 30
Per le aree CUN si è scelto di non considerare nella valutazione gli Atenei con un numero di docenti al di sotto di una certa soglia. Tale soglia è stata calcolata per ogni area come l’1,64% del numero massimo di docenti presenti in un singolo Ateneo per l’area in oggetto.
La percentuale è stata fissata in modo da poter escludere Atenei con Aree CUN con un solo docente. In particolare è risultato 1,64 = 100 x 1/61 dove 61 è il più piccolo, fra tutte le Aree CUN, numero massimo di docenti appartenenti ad una stessa area CUN.
Sono credibili le classifiche CENSIS-Repubblica?
Il lettore che ci ha seguito fino a questo punto è in grado di rispondere da solo.
L’analisi dei metodi e degli indicatori ha dimostrato che alcuni esiti paradossali che saltano subito all’occhio non sono infortuni di percorso, ma derivano da falle strutturali di una classifica fai-da-te, precaria nei metodi e nelle fonti dei dati.
Gli studenti e le loro famiglie comprano la guida e la consultano nella speranza di poter fare una scelta oculata a fronte di costi che la famiglia dovrà sostenere. Che servizio offre agli studenti e alle loro famiglie una guida che nella classifica della ricerca di un’area importante colloca al terzo posto nazionale una università con soli quattro docenti? Piuttosto, contribuisce ad accrescere la confusione e il disorientamento di chi deve scegliere.
Giunti alla fine, è lecito domandarsi chi siano i principali beneficiari di una guida di questo genere.
Gli studenti e le loro famiglie?
Oppure serve solo a chi la pubblica, mettendola in vendita a poco meno di 10 Euro a copia?


{kind=link}
[…] siamo appoggiati alle considerazioni fatte su ROARS (https://www.roars.it/le-classifiche-censis-repubblica-sono-credibili/) circa la classifica Censis 2014/2015, la cui nota metodologica è molto simile a quella […]